Recently, several works proposed the convolution of a neural network with a Gaussian as a smoothed classifier for provably robust classification. We show that adversarially training this smoothed classifier significantly increases its provable robustness through extensive experiments, achieving state-of-the-art provable robustness on CIFAR10 and Imagenet, as shown in the tables below.
Update 09/10/2019: By combining pre-training and semi-supervision with SmoothAdv, we obtain significant improvement over SmoothAdv alone.
| radius (Imagenet) | 0.5 | 1 | 1.5 | 2 | 2.5 | 3 | 3.5 |
|---|---|---|---|---|---|---|---|
| Cohen et al. (%) | 49 | 37 | 29 | 19 | 15 | 12 | 9 |
| Ours (%) | 56 | 45 | 38 | 28 | 26 | 20 | 17 |
| radius (CIFAR-10) | 0.25 | 0.5 | 0.75 | 1.0 | 1.25 | 1.5 | 1.75 | 2.0 | 2.25 |
|---|---|---|---|---|---|---|---|---|---|
| Cohen et al. (%) | 61 | 43 | 32 | 22 | 17 | 13 | 10 | 7 | 4 |
| Ours (%) | 73 | 58 | 48 | 38 | 33 | 29 | 24 | 18 | 16 |
| + Pre-training (%) | 80 | 62 | 52 | 38 | 34 | 30 | 25 | 19 | 16 |
| + Semi-supervision (%) | 80 | 63 | 52 | 40 | 34 | 29 | 25 | 19 | 17 |
| + Both (%) | 81 | 63 | 52 | 37 | 33 | 29 | 25 | 18 | 16 |
We also achieved state-of-the-art provable robustness on CIFAR10, with norm , as shown in the table below. This is by noting that the ball of radius is contained in the -ball of radius , and invoking our provable robustness for this radius.
| Model | Provable Acc @ 2/255 | Standard Acc |
|---|---|---|
| Ours | 68.2 | 87.2 |
| Carmon et al. | 63.8 ± 0.5 | 80.7 ± 0.3 |
| Wong & Kolter 2018b (single) | 53.9 | 68.3 |
| Wong & Kolter 2018b (ensemble) | 63.6 | 64.1 |
| Interval Bound Propagation | 50.0 | 70.2 |
Introduction
It is now well-known that deep neural networks suffer from the brittleness problem: A small change in an input image imperceptible to humans can cause dramatic change in a neural network’s classification of the image. Such a perturbed input is known as an adversarial example and is by now immortalized in the famous picture below from Goodfellow et al.
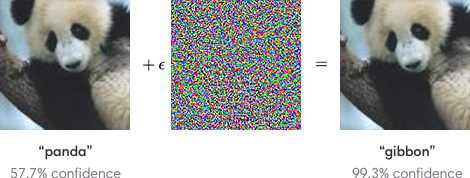
As deep neural networks enter consumer and enterprise products of various forms, this brittleness can possibly have devastating consequences (Brown et al. 2018, Athalye et al. 2017, Evtimov & Eykholt et al. 2018, Li et al. 2019). Most strikingly, Tencent Keen Security Lab recently demonstrated that the neural network underlying Tesla Autopilot can be fooled by an adversarially crafted marker on the ground into swerving into the opposite lane.
Adversarial Attack and Defense
Given the importance of the problem, many researchers have formulated security models of adversarial attacks, along with ways to defend against adversaries in such models. In the most popular security model in the academic circle today, the adversary is allowed to perturb an input by a small noise bounded in -norm, in order to cause the network to misclassify it. Thus, given a loss function , a norm bound , an input , its label , and a neural network , the adversary tries to find an input , within -distance of , that maximizes the loss , i.e. it solves the following optimization problem
If has trainable parameters , then the defense needs to find the parameters that minimizes , for sampled from the data distribution , i.e. it solves the following minimax problem
Empirically, during an attack, the adversarial input can be obtained approximately by solving the max problem using gradient descent, making sure to project back to the -ball after each step. This is known as the PGD attack (Kurakin et al., Madry et al.), short for “project gradient descent.” During training by the defense, for every sample , this estimate of can be plugged into the min problem for gradient descent of . This is known as Adversarial Training, or PGD training specifically when PGD is used for finding .
Empirical Robust Accuracy
Currently, the standard benchmark for measuring the strength of a model’s adversarial defense is the model’s (empirical) robust accuracy on various standard datasets like CIFAR-10 and Imagenet. This accuracy is calculated by attacking the model with a strong empirical attack (like PGD) for every sample of the test set. The percentage of the test set that the model is still able to correctly classify is the empirical robust accuracy.
For example, consider an adversary allowed to perturb an input by in norm. On an image, this means that the adversary can change the color of each pixel by at most 8 units (out of 255 total) in each color channel — a rather imperceptible perturbation. Currently, the state-of-the-art empirical robust accuracy against such an adversary on CIFAR-10 hovers around 55% (Zhang et al. 2019, Hendrycks et al. 2019), meaning that the best classifier can only withstand a strong attack on about 55% of the samples in CIFAR-10. Contrast this with the state-of-the-art nonrobust accuracy on CIFAR-10 of >95%. Thus it’s clear that adversarial robustness research still has a long way to go.
Provable Robustness via Randomized Smoothing
Note that the empirical robust accuracy is only an upper bound on the true robust accuracy. This is defined by hypothetically replacing the strong empirical attack used in empirical robust accuracy with the ideal attack able to find exactly for every . Thus, nothing in principle prevents a stronger empirical attack from further lowering the empirical robust accuracy of a model. Indeed, except a few notable cases like PGD (Madry et al.), we have seen most claims of adversarial robustness broken down by systematic and thorough attacks (as examples, see Carlini & Wagner 2016, Carlini & Wagner 2017, Athalye et al. 2017, Uesato et al. 2018, Athalye et al. 2018, Engstrom et al. 2018, Carlini 2019).
This has motivated researchers into developing defenses that can certify the absence of adversarial examples (as prominent examples, see Wong & Kolter 2018, Katz et al. 2017, and see Salman et al. 2019 for a thorough overview of these techniques). Such a defense is afforded a provable (or certified) robust accuracy on each dataset, defined as the percentage of the test set that can be proved to have no adversarial examples in its neighborhood. In contrast with empirical robust accuracy, provable robust accuracy is a lower bound on the true robust accuracy, and therefore cannot be lowered further by more clever attacks. The tables in the beginning of our blog post, for example, display provable robust accuracies on CIFAR-10 and Imagenet.
Until recently, most such certifiable defenses have not been able to scale to large networks and datasets (Salman et al. 2019), but a new technique called randomized smoothing (Lecuyer et al., Li et al., Cohen et al.) was shown to bypass this limitation, obtaining highly-nontrival certified robust accuracy on Imagenet (Cohen et al.). We now briefly review randomized smoothing.
Definition
Consider a classifier from to classes . Randomized smoothing is a method that constructs a new, smoothed classifier from the base classifier . The smoothed classifier assigns to a query point the class which is most likely to be returned by the base classifier under isotropic Gaussian noise perturbation of , i.e.,
where , and the variance is a hyperparameter of the smoothed classifier (it can be thought to control a robustness/accuracy tradeoff). In Cohen et al., is a neural network.
Prediction
To estimate , one simply has to
- Sample a collection of Gausian samples .
- Predict the class of each using the base classifier .
- Take the majority vote of the ’s as the final prediction of the smoothed classifier at .
Certification
The robustness guarantee presented by Cohen et al. is as follows: suppose that when the base classifier classifies , the (most popular) class is returned with probability , and the runner-up class is returned with probability . We estimate and using Monte Carlo sampling and confidence intervals1. Then the smoothed classifier is robust around within the radius
where is the inverse of the standard Gaussian CDF. Thus, the bigger is and the smaller is, the more provably robust is.
Training
Cohen et al. simply trained the base classifier under Gaussian noise data augmentation with cross entropy loss, i.e. for each data point , sample and train on the example . With this simple training regime applied to a Resnet-110 base classifier, they were able to obtain significant certified robustness on CIFAR-10 and Imagenet, as shown in our tables.
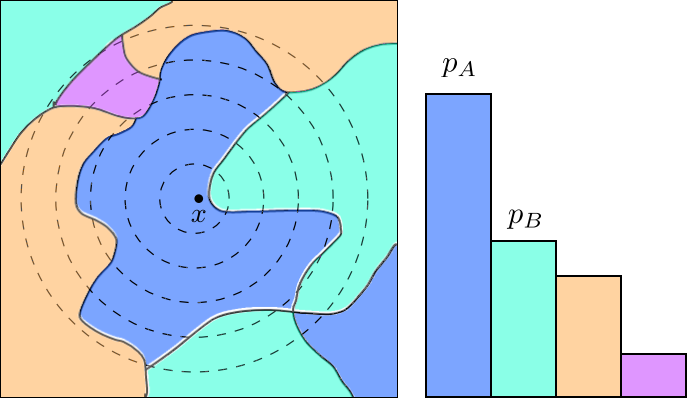
An Illustration
The following figures modified from Cohen et al. illustrate randomized smoothing. The base classifier partitions the input space into different regions with different classifications, colored differently in the left figure. The regions’ Gaussian measures (under the Gaussian whose level curves are shown as dashed lines) are shown as a histogram on the right. The class corresponding to the blue region is the output of the smoothed classifier ; the class corresponding to the cyan region is the runner-up class. If is large enough and is small enough, then we can prove that for all , i.e. is robust at for radius .
Adversarially Training the Smoothed Classifier
Intuitively, adversarial training attempts to make a classifier locally flat around input sampled from a data distribution. Thus it would seem that adversarial training should make it easier to certify the lack of adversarial examples, despite having no provable guarantees itself. Yet historically, it has been difficult to execute this idea (Salman et al. 2019, and folklore), with the closest being Xiao et al.
It is hence by no means a foregone conclusion that adversarial training should improve certified accuracy of randomized smoothing. A priori there could also be many ways these two techniques can be combined, and it is not clear which one would work best:
- Train the base classifier to be adversarially robust, simultaneous with the Gaussian data augmentation training prescribed in Cohen et al..
- Find an adversarial example of the base classifier , then add Gaussian noise and train.
- Add Gaussian noise and find an adversarial example of in the neighborhood of this Gaussian perturbation. Train on this adversarial example.
- Find an adversarial example of the smoothed classifier , then train on this example.
It turns out that certified accuracies of these methods follow the order (1) < (2) < (3) < (4), with (4) achieving the highest certified accuracies (see our paper). Indeed, in hindsight, if is the classifer doing the prediction, then we should be adversarially training , and not . In the rest of the blog post, we lay out the details of (4).
Randomized Smoothing for Soft Classifiers
Neural networks typically learn soft classifiers, namely, functions , where is the set of probability distributions over . During prediction, the soft classifier is argmaxed to return the final hard classification. We therefore consider a generalization of randomized smoothing to soft classifiers. Given a soft classifier , its associated smoothed soft classifier is defined as
Let and denote the hard and soft classifiers learned by the neural network, respectively, and let and denote the associated smoothed hard and smoothed soft classifiers. Directly finding adversarial examples for the smoothed hard classifier is a somewhat ill-behaved problem because of the argmax, so we instead propose to find adversarial examples for the smoothed soft classifier . Empirically we found that doing so will also find good adversarial examples for the smoothed hard classifier.
Finding Adverarial Examples for Smoothed Soft Classifier
Given a labeled data point , we wish to find a point which maximizes the loss of in an ball around for some choice of loss function. As is canonical in the literature, we focus on the cross entropy loss . Thus, given a labeled data point our (ideal) adversarial perturbation is given by the formula:
We will refer to the above as the SmoothAdv objective. The SmoothAdv objective is highly non-convex, so as is common in the literature, we will optimize it via projected gradient descent (PGD), and variants thereof. It is hard to find exact gradients for SmoothAdv, so in practice we must use some estimator based on random Gaussian samples.
Estimating the Gradient of SmoothAdv
If we let denote the SmoothAdv objective, then
However, it is not clear how to evaluate the expectation inside the log exactly, as it takes the form of a complicated high dimensional integral. Therefore, we will use Monte Carlo approximations. We sample i.i.d. Gaussians , and use the plug-in estimator for the expectation:
It is not hard to see that if is smooth, this estimator will converge to as we take more samples.
SmoothAdv is not the Naive Objective
We note that SmoothAdv should not be confused with the similar-looking objective
where the and have been swapped compared to SmoothAdv, as suggested in section G.3 of Cohen et al. This objective, which we shall call naive, is the one that corresponds to finding an adversarial example of that is robust to Gaussian noise. In contrast, SmoothAdv directly corresponds to finding an adversarial example of . From this point of view, SmoothAdv is the right optimization problem that should be used to find adversarial examples of . This distinction turns out to be crucial in practice: empirically, Cohen et al found attacks based on the naive objective not to be effective. In our paper, we perform SmoothAdv-attack on Cohen et al.’s smoothed model and find, indeed, that it works better than the Naive objective, and it performs better with more Gaussian noise samples used to estimate its gradient.
Adversarially Training Smoothed Classifiers
We now wish to use our new SmoothAdv attack to boost the adversarial robustness of smoothed classifiers. As described in the beginning of this blog post, in (ordinary) adversarial training, given a current set of model parameters and a labeled data point , one finds an adversarial perturbation of for the current model, and then takes a gradient step for the model parameters , evaluated at the point . Intuitively, this encourages the network to learn to minimize the worst-case loss over a neighborhood around the input.
What is different in our proposed algorithm is that we are finding the adversarial example with respect to the smoothed classifier using the SmoothAdv objective, and we are training at this adversarial example with respect to the SmoothAdv objective, estimated by the plug-in estimator.
where are the parameters of at time , , and is a learning rate.
More Data: Pretraining and Semisupervision
Hendrycks et al. showed that pre-training on Imagenet can improve empirical adversarial robustness on CIFAR-10 and CIFAR-100. Similarly, Carmon et al. showed that augmenting supervised adversarial training with unsupervised training on a carefully selected unlabeled dataset confers significant robustness improvement. We adopt these ideas for randomized smoothing and confirm that these techniques are highly beneficial for certified robustness as well, especially for smaller radii (though unfortunately their combination did not induce combined improvement). See the tables below.
Results
Over the course of the blog post, we have introduced several hyperparameters, such as 1) , the radius of perturbation used for adversarial training, 2) , the number of Gaussian noise samples, 3) , the standard deviation of the Gaussian noise. We also did not mention other hyperparameters like , the number of iterations used for PGD iterations, or the usage of DDN, an alternative attack to PGD that has been shown to be effective for -perturbations (Rony et al.). In our paper we do extensive analysis of the effects of these hyperparameters, to which we refer interested readers.
Taking the max over all such hyperparameter combinations for each perturbation radius, we obtain the upper envelopes of the certified accuracies of our method vs the upper envelopes of Cohen et al. in the tables in the beginning of this post, which we also replicate here for convenience.
| radius (Imagenet) | 0.5 | 1 | 1.5 | 2 | 2.5 | 3 | 3.5 |
|---|---|---|---|---|---|---|---|
| Cohen et al. (%) | 49 | 37 | 29 | 19 | 15 | 12 | 9 |
| Ours (%) | 56 | 43 | 37 | 27 | 25 | 20 | 16 |
| radius (CIFAR-10) | 0.25 | 0.5 | 0.75 | 1.0 | 1.25 | 1.5 | 1.75 | 2.0 | 2.25 |
|---|---|---|---|---|---|---|---|---|---|
| Cohen et al. (%) | 60 | 43 | 32 | 23 | 17 | 14 | 12 | 10 | 8 |
| Ours (%) | 74 | 57 | 48 | 38 | 33 | 29 | 24 | 19 | 17 |
| + Pre-training (%) | 80 | 63 | 52 | 39 | 36 | 30 | 25 | 20 | 17 |
| + Semi-supervision (%) | 80 | 63 | 53 | 39 | 36 | 32 | 25 | 20 | 18 |
| + Both (%) | 82 | 65 | 52 | 38 | 34 | 30 | 25 | 21 | 18 |
Conclusion
In this blog post, we reviewed adversarial training and randomized smoothing, a recently proposed provable defense. By adversarially training the smoothed classifier — and carefully getting all the details right — we obtained the state-of-the-art provable robustness on CIFAR-10 and Imagenet, demonstrating significant improvement over randomized smoothing alone.
Acknowledgements
This blog post presented work done by Hadi Salman, Greg Yang, Jerry Li, Huan Zhang, Pengchuan Zhang, Ilya Razenshteyn, and Sebastien Bubeck. We would like to thank Zico Kolter, Jeremy Cohen, Elan Rosenfeld, Aleksander Madry, Andrew Ilyas, Dimitris Tsipras, Shibani Santurkar, Jacob Steinhardt for comments and discussions during the making of this paper.
-
We actually estimate a lower bound of and an upper bound of with high probability, and substitute and for and everywhere. This is an overestimate, so our guarantee holds except for a small probability that the estimates are wrong. See Cohen et al. or our paper for more details. ↩