Can we find a general theory for randomized smoothing? We show that for an appropriate notion of “optimal”, the best smoothing distribution for any norm has level sets given by the Wulff Crystal of that norm.
In the previous post, we discussed how to learn provably robust image classifiers via randomized smoothing and adversarial training, robust against adversarial perturbations. There, the choice of Gaussian for the smoothing distribution would only seem most natural. What if the adversary is for ? What kind of distributions should we smooth our classifier with? In this post, we take a stroll through a result of our recent preprint Randomized Smoothing of All Shapes and Sizes that answers this question, which curiously leads us to the concept of Wulff Crystals, a crystal shape studied in physics for more than a century. Empirically, we use this discovery to achieve state-of-the-art in provable robustness in CIFAR10 and Imagenet.
Introduction
While neural networks have excelled at image classification tasks, they are vulnerable to adversarial examples; imperceptible perturbations of the input that change the predicted class label (Szegedy et al. 2014), as illustrated by the following image from Madry and Schmidt’s blog post.
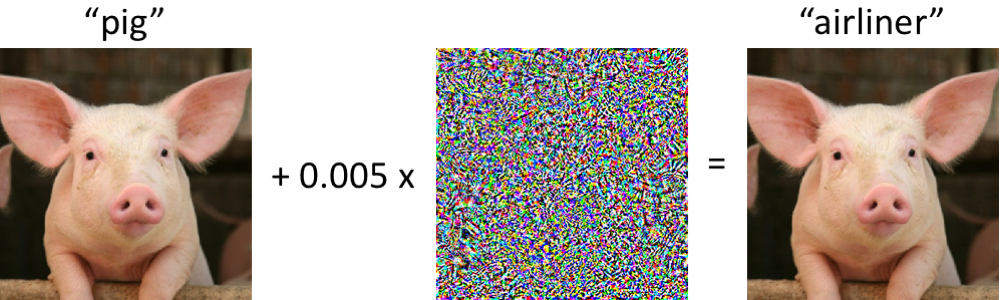
This has most often been formalized in terms of the following desiderata: Let be a set of “allowed adversarial perturbations,” such as . Consider a classifier that maps an input (e.g. an image) to one of a number of classes (e.g. the label “cat”). Then we say a function is robust at to perturbations from if and share the same labels for all .
It is easy to create such inputs by perturbing a data point by, for example, projected gradient descent (Madry et al. 2018) (see our previous post for a concise overview). This raises important safety concerns as machine learning is increasingly deployed in contexts such as healthcare and autonomy.
The community has developed a plethora of techniques toward mending a model’s vulnerability to adversarial examples: adversarial training, gradient masking, discretizing the input, etc. Yet these “empirical defenses” are usually short-lived and completely broken by newer, more powerful attacks (Athalye et al. 2018).
This motivates the study of certifiably robust defenses, which have emerged to stop this escalating arm race. In such a defense, the classifier not only labels the input, but also yields a certificate that says “not matter how the input is perturbed by a vector in , my label will not change.”
We focus on randomized smoothing, a method popularized by Lecuyer et al. 2018, Li et al. 2018, and Cohen et al. 2019 that attains state-of-the-art certifiable robustness guarantees. The core idea is simple: given a classifier and input , instead of feeding directly to , we can sample lots of random noise, say from a normal distribution, , and output the most commonly predicted class among the predictions . It turns out that this scheme can guarantee this most common class stays unchanged when the input is perturbed by vectors of small norm. We will more formally discuss this technique below. For more background, we also welcome the reader to see our previous post.
For the most part, prior works on randomized smoothing has focused on smoothing with a Gaussian distribution and defending against adversary, neglecting other traditionally important threat models like or . Here, we take a step back and ask the following:
What’s the optimal smoothing distribution for a given norm?
In answering, we will achieve state-of-the-art empirical results for robustness on CIFAR-10 and ImageNet datasets. In the table below we show the certified accuracies comparing our choice of smoothing with the Uniform distribution to the previous state-of-the-art which performed smoothing with the Laplace distribution. Here, each percentage indicates the fraction of the test set for which we both 1) classify correctly and 2) guarantee there is no adversarial example within the corresponding radius.
| ImageNet | Radius | 0.5 | 1.0 | 1.5 | 2.0 | 2.5 | 3.0 | 3.5 | 4.0 |
|---|---|---|---|---|---|---|---|---|---|
| Uniform, Ours (%) | 55 | 49 | 46 | 42 | 37 | 33 | 28 | 25 | |
| Laplace, Teng et al. (2019) (%) | 48 | 40 | 31 | 26 | 22 | 19 | 17 | 14 |
| CIFAR-10 | Radius | 0.5 | 1.0 | 1.5 | 2.0 | 2.5 | 3.0 | 3.5 | 4.0 |
|---|---|---|---|---|---|---|---|---|---|
| Uniform, Ours (%) | 70 | 59 | 51 | 43 | 33 | 27 | 22 | 18 | |
| Laplace, Teng et al. (2019) (%) | 61 | 39 | 24 | 16 | 11 | 7 | 4 | 3 |
Background
Let us first introduce some background on randomized smoothing.
Definition. Let be a finite set of labels (e.g. “cats”, “dogs”, etc). Let be a classifier that outputs one of these labels given an input. Given a distribution on , we can smooth with to produce a new classifier , called the smoothed classifier, which is defined at any point as
A moment of thought should show that is the same classifier as the one produced by the “majority vote” procedure for randomized smoothing described in the introduction, if we have an infinite number of random noises .
Slightly less intuitively, we can also define in the following way, in terms of the decision regions of the base classifier :
Here and denotes the translation of by . Note is the same as the measure of under the recentered distribution of at , and is the maximum such measure over all decision regions .
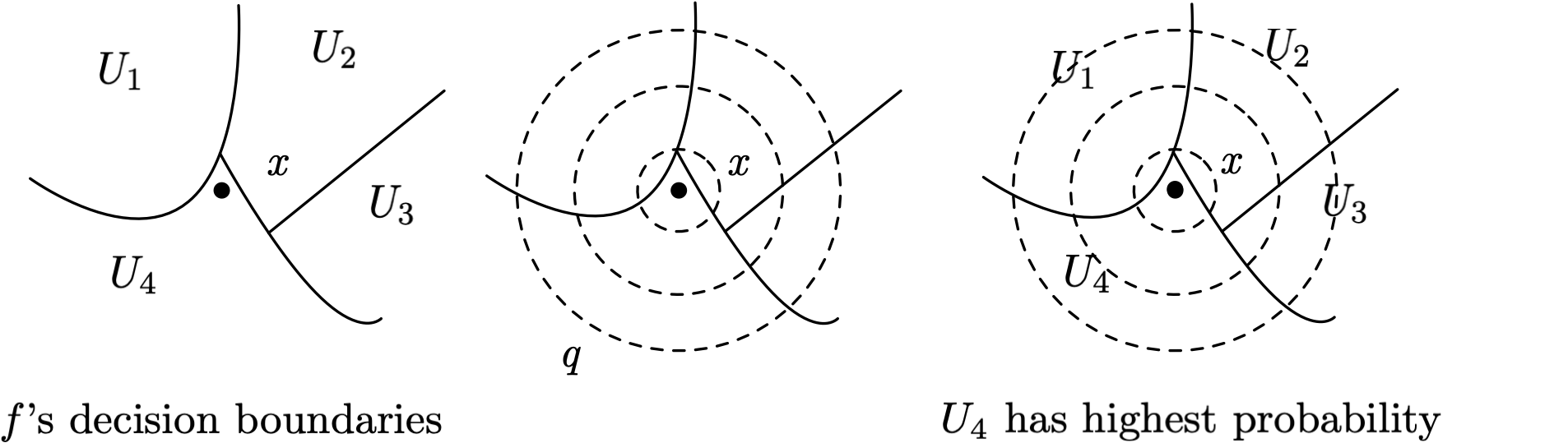
Now let’s turn our attention to what robustness properties arise in , the smoothed classifier. To do so, we’ll need to consider the worst case over all possible decision regions that may arise, since the base classifier is an arbitrary neural network.
Definition. The growth function with respect to distribution is defined as,
Its interpretation is: out of all sets (i.e. all possible decision regions) with initial measure , what is the most that its measure can increase when we shift the center of by a vector ? Note this is a property of alone and does not depend on .
For example, consider a 2D Gaussian measure with a perturbation . Let and consider two possible choices: let be the bottom-left quadrant and be the top-right quadrant. They both have measure under . It’s easy to see that after a shift in the distribution’s center by , will have higher measure than .
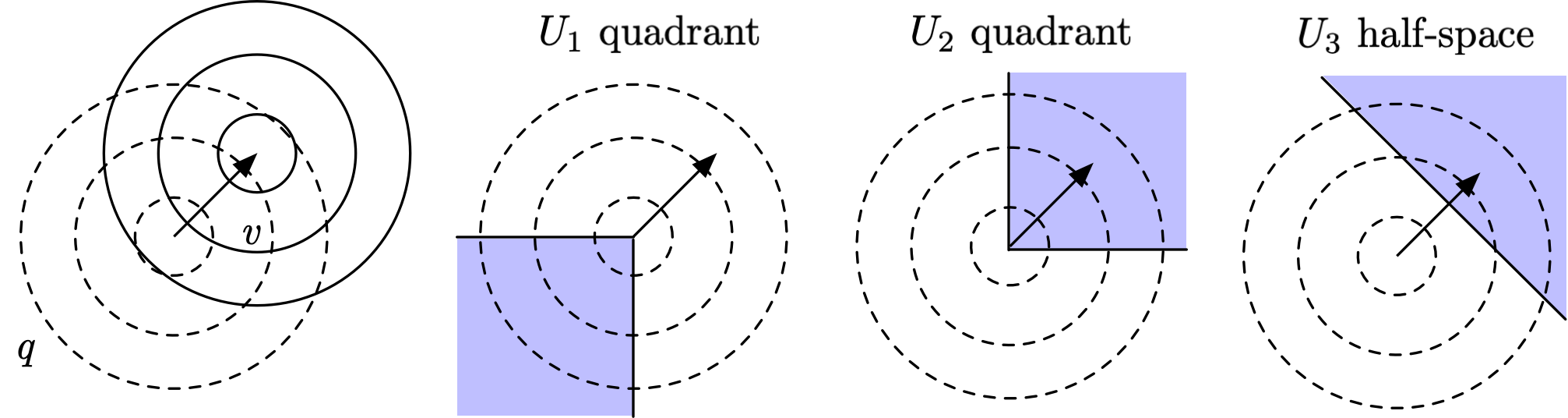
It turns out that here the most extreme choice of with measure , in terms of maximizing the growth function, is , the half-space formed with a hyper-plane perpendicular to , with boundary positioned such that .
To see this, think of the problem of finding the most extreme as a problem of “maximizing value under budget constraint.” Each vector added to will “cost” , and the total cost is at most , the measure of under . At the same time, each will also bring in a “profit” of , and the total profit is , the measure of under . Thus a greedy cost-benefit analysis would suggest that we sort all by in descending order, and add to the top s until we hit our cost budget, i.e. . In the above example of being Gaussian, the ratio changes only along the direction and stays constant in each hyperplane perpendicular to , so the above reasoning confirms that the half-space above is the maximizing . The growth function in this example would then read , which turns out to have a simple expression that we shall describe below.
If the smoothed classifier assigns label to input , then has the largest measure under among all decision regions . Thus, if does not shrink in -measure too much when it is shifted by , or equivalently if the complement of does not grow too much in -measure. This intuition can be captured more formally with the growth function:
Result. Suppose for a base classifier , we have . Then the smoothed classifier will not change its prediction under perturbation set if
Back to our 2D Gaussian example, and suppose we have and recall that we’re interested in a perturbation . From the above result we know that will not change its prediction as long as . So we need to calculate , which is the measure of the half-space we identified earlier, under the distribution shifted by . Where is the boundary of the half-space? Consider a change of basis so that the x-axis follows the direction of such as in the center figure below. The boundary occurs at . What’s the measure of this half-space under shifted by ? Exactly .
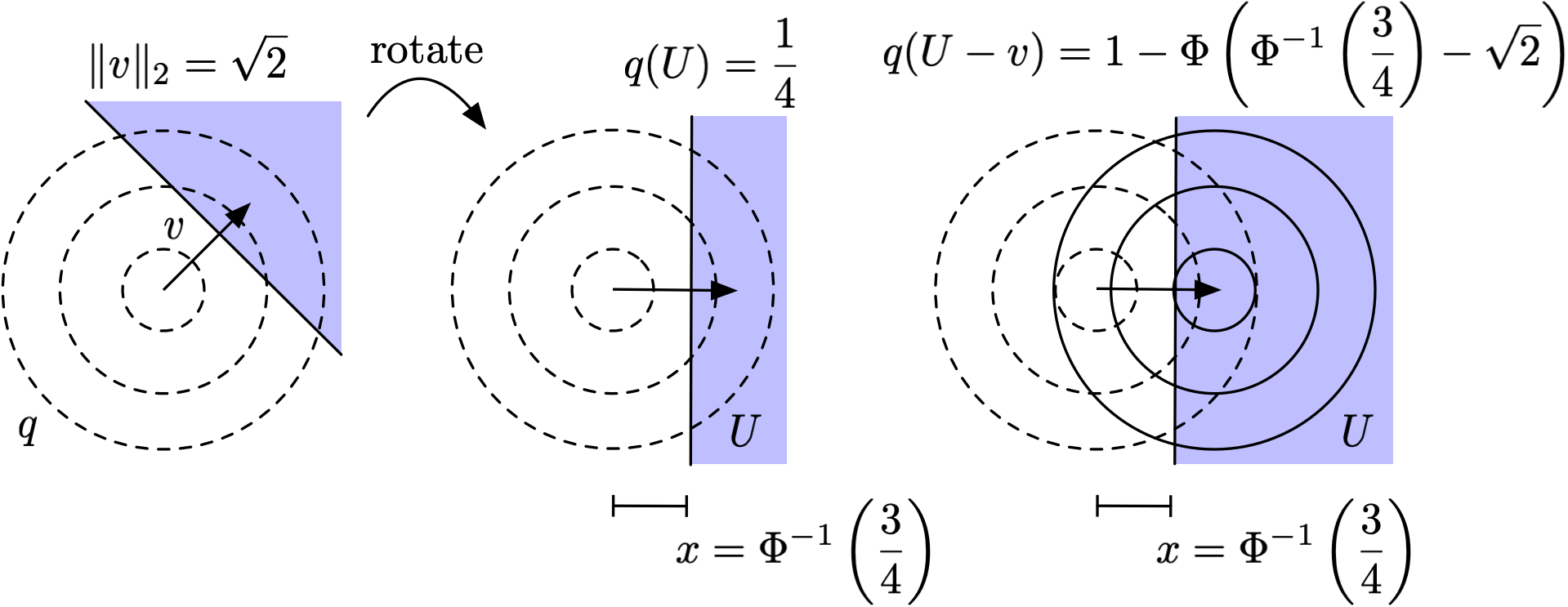
Therefore,
so the classifier is not robust to the perturbation if . On the other hand, following similar logic we can calculate the growth function for , which tells us
so the classifier is robust to the perturbation if .
More generally Gaussian smoothing yields the bound derived in Cohen et al. 2019,
The Optimal Smoothing Distributions
Here we provide intuition for the question we want to answer:
What is the best distribution to smooth with if we want robustness?
First let’s simplify and consider a uniform distribution over a convex set where . By inspection,
In this situation, the that obtains the for the growth function is any subset of with volume , unioned with the complement of . For example, see the left figure below, in which the area of is , satisfying where is the measure of our uniform distribution.
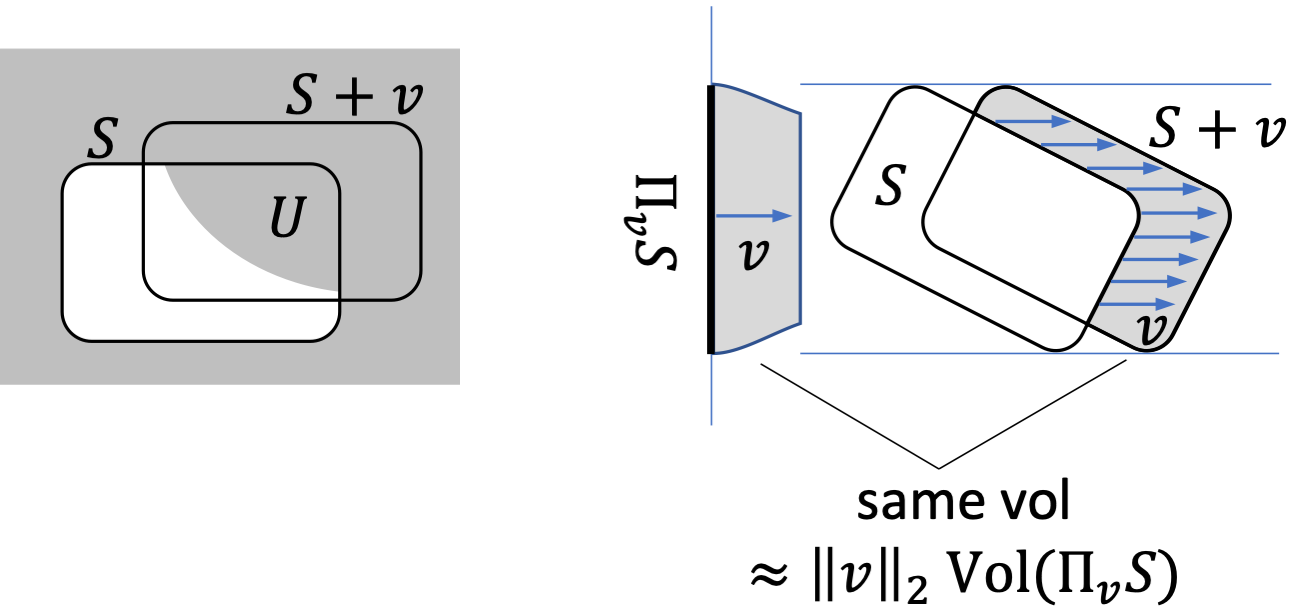
Now consider an infinitesimal translation by . As , the volume of approaches times the volume of the projection of along , in terms of -dimensional Lesbegue measure. Here, is formally defined as . See the right figure above for an example in 2D – the projection of along yields the length between the two blue horizontal lines.
This intuition justifies the following limits:
In the context of randomized smoothing, recall that the smoothed classifier is robust to a perturbation as long as . Here in our uniform distribution example, this means that is robust to small perturbations as long as
If we consider the worst-case perturbation for a fixed model, we have a smoothed classifier robust to a perturbation set as long as
Importantly, the model is more robust as decreases. So a natural question to ask is, which set , our smoothing distribution, minimizes this quantity over all convex sets of volume ?
It turns out the answer is the Wulff Crystal, a shape from theoretical physics.
Wulff Crystals
Definition. The Wulff Crystal with respect to is defined as the unit ball of the norm dual to , where with sampled uniformly from vertices of .
Let’s unpack this a bit. Recall dual norm is defined as,
For example, it’s well known that the dual norm of the norm is the norm where .
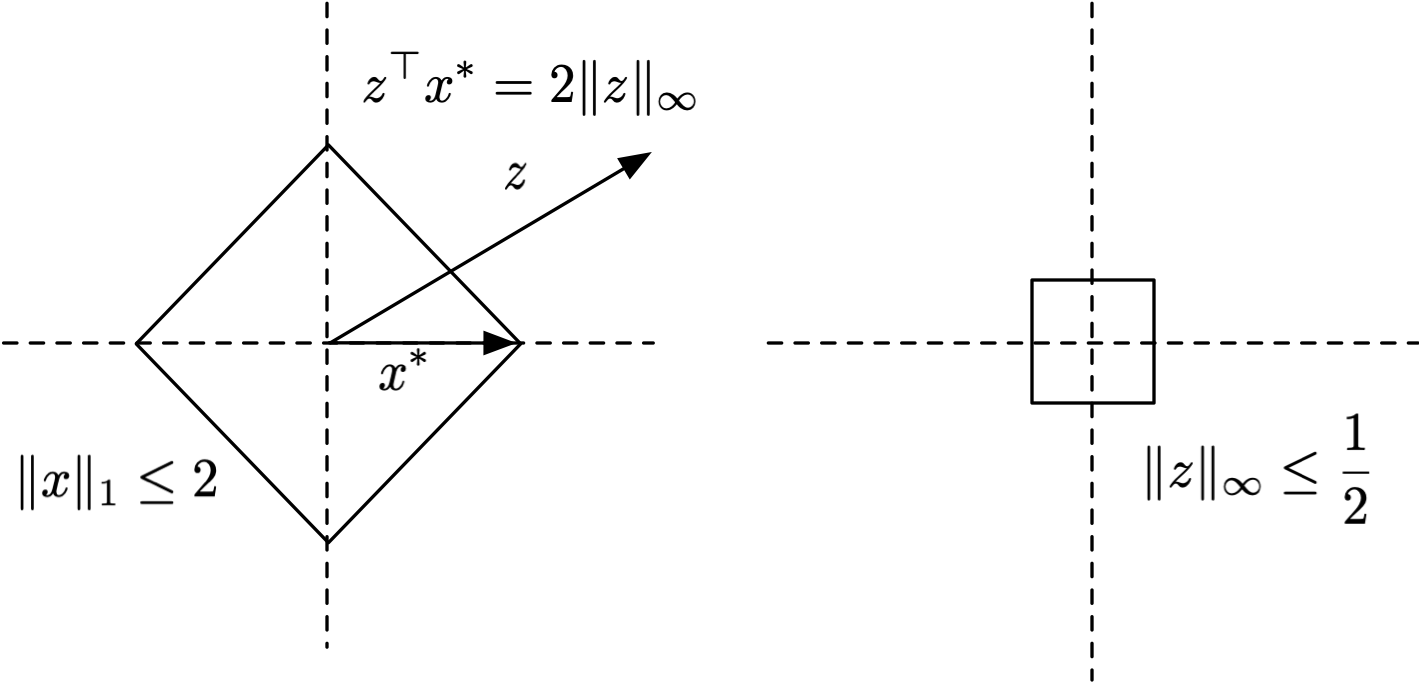
Now suppose we’re interested in the Wulff Crystal for , where is the rhombus in two dimensions, which has vertices . Thus,
So the constraint corresponds to constraining i.e. a scaled version of the rhombus. What’s the dual of this? For any , , so the Wulff Crystal is the ball .
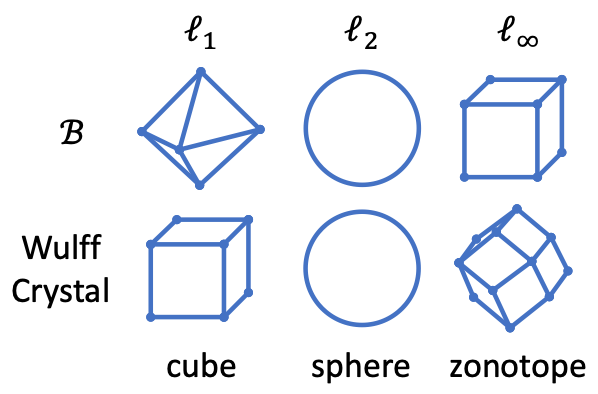
Below we show a few examples of Wulff Crystals for different perturbation sets .
- For the cross-polytope, the Wulff Crystal is a cube.
- For the sphere, the Wulff Crystal is a sphere.
- For the cube, the Wulff Crystal is the zonotope (i.e. Minkowski sum) of vectors . In two dimensions this is a rhombus and in three dimensions it is a rhombic dodecahedron, but in higher dimensions there is no simpler description of it than as the zonotope of the vectors .
Result. For any , the Wulff Crystal with respect to minimizes the quantity
among all measurable (not necessarily convex) sets of the same volume, and when is sufficiently symmetric (e.g. balls).
In other words, setting to be the Wulff Crystal minimizes the growth function, and therefore makes more robust. So this covers cases of smoothing with a distribution that’s uniform over a set . What about the more general (i.e. non-uniform) case? It turns out the Wulff Crystal remains optimal, in that it determines the best shape of the distribution’s level sets.
Result. Let be any reasonable distribution with an even density function. Among all reasonable and even density functions (i.e. ) with superlevel sets with the same volumes as those of , the quantity
is minimized by the distribution with superlevel sets proportional to the Wulff Crystal with respect to . For proof, see our paper.
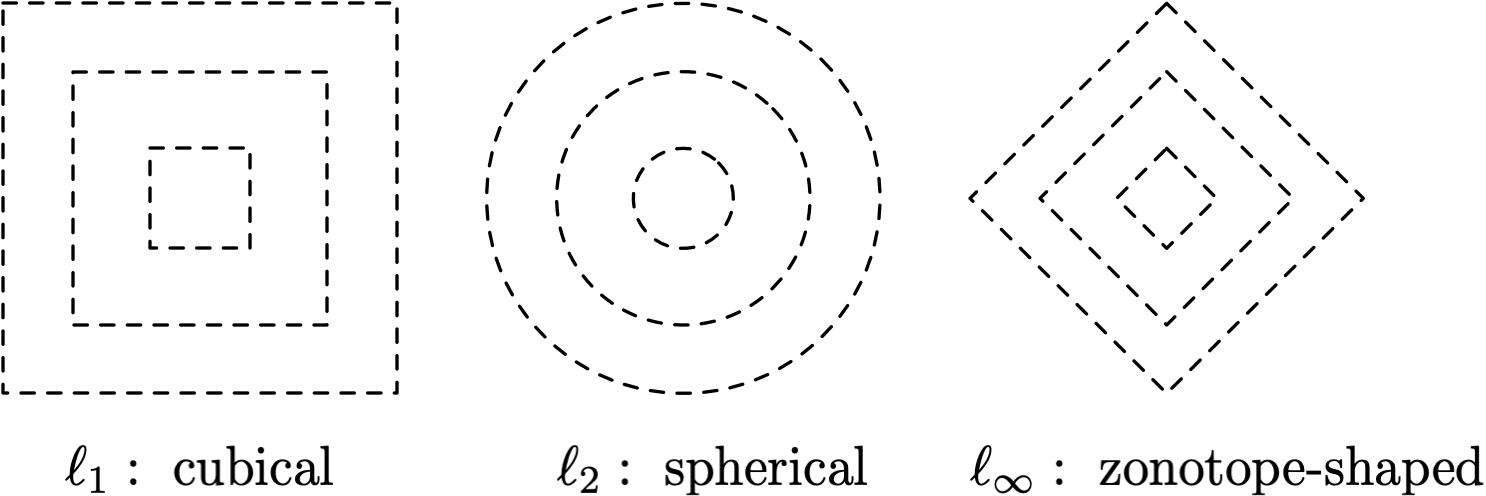
This means that:
- For the ball, the distribution should have cubical level sets.
- For the ball, the distribution should have spherical level sets.
- For the ball, the distribution should have zonotope-shaped level sets.
We note that an important difference between this result and the previous one is that it applies specifically to the case where , not the more general case for any value of . In the context of randomized smoothing, this corresponds to the case where the smoothed classifier correctly classifies the class , but only barely i.e.
This is an important case, as such inputs are close to the decision boundary, and Wulff Crystal distributions yield the best robustness guarantee for such hard points.
Another way to look at this: Any choice of smoothing distribution implies a different certified radius against an adversary, given a fixed value of . For example, below we plot the radii for the adversary and for Gaussian, Laplace, and Uniform distributions. What this theorem says is that the slope of the curve at will be highest for the distribution with Wulff Crystal level sets.
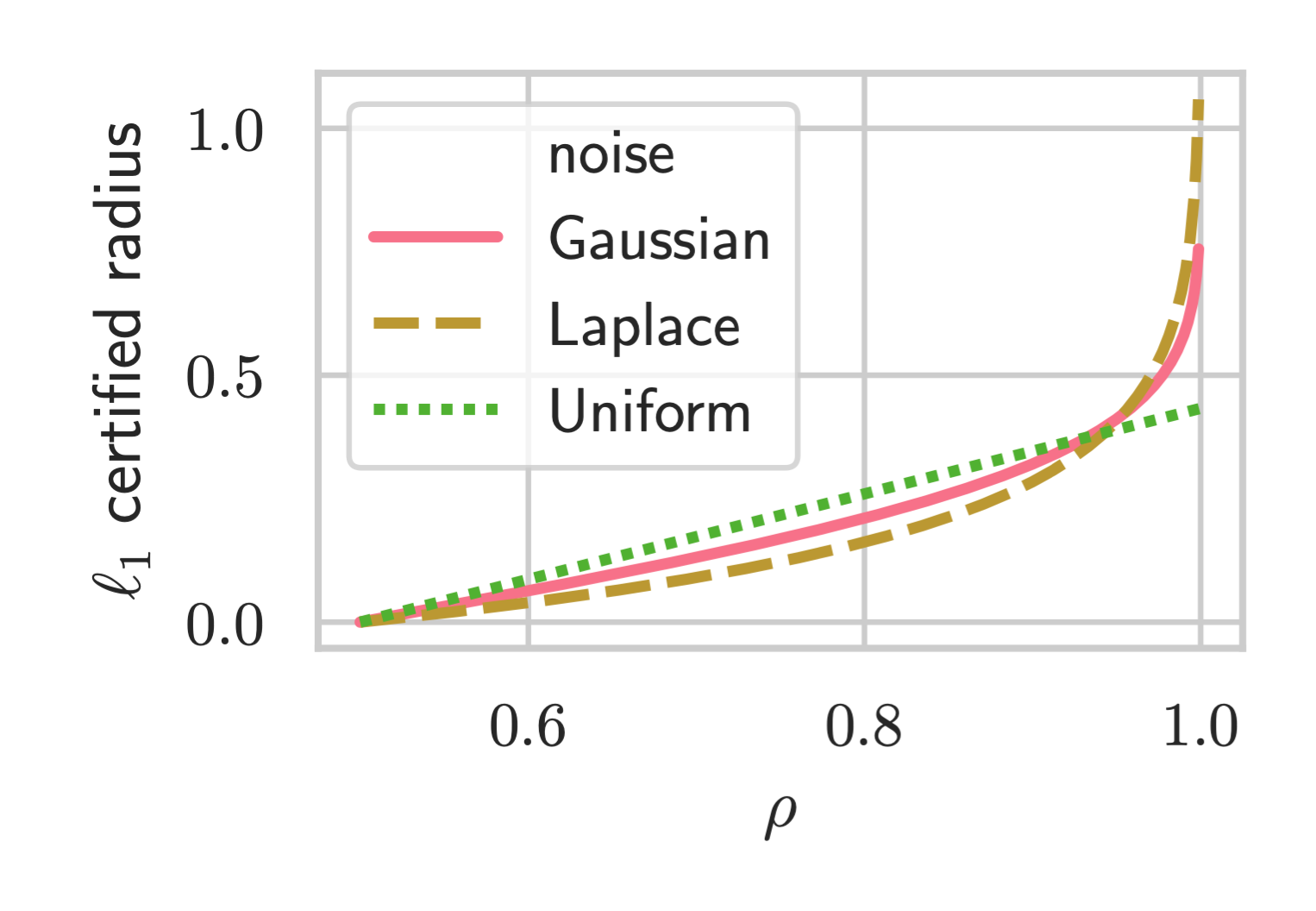
Empirical Results
We ran an extensive suite of experiments on ImageNet and CIFAR-10 to verify our Wulff Crystal theory. In this section we’ll focus on the adversary, whose Wulff Crystal is cubical. We therefore compare the following distributions:
- Uniform (cubical), .
- Gaussian (non-cubical), .
- Laplace (non-cubical), .
We also compare against a larger array of other distributions in our paper, but we shall focus on just the above in this post. We use Wide ResNet for all of our experiments.
Definition. The certified robust accuracy at an radius of is the fraction of the test set the smoothed classifier correctly classifies and certifies robust for at least a ball of size . Since larger noise variances naturally lead to larger robust radii but trade off against accuracy, we tune over the noise variance and consider the best certified robust accuracy among all values of the hyper-parameter.
Below we show the certified top-1 accuracies for CIFAR-10 and ImageNet. We find that the Uniform distribution performs best, significantly better than Gaussian and Laplace distributions.
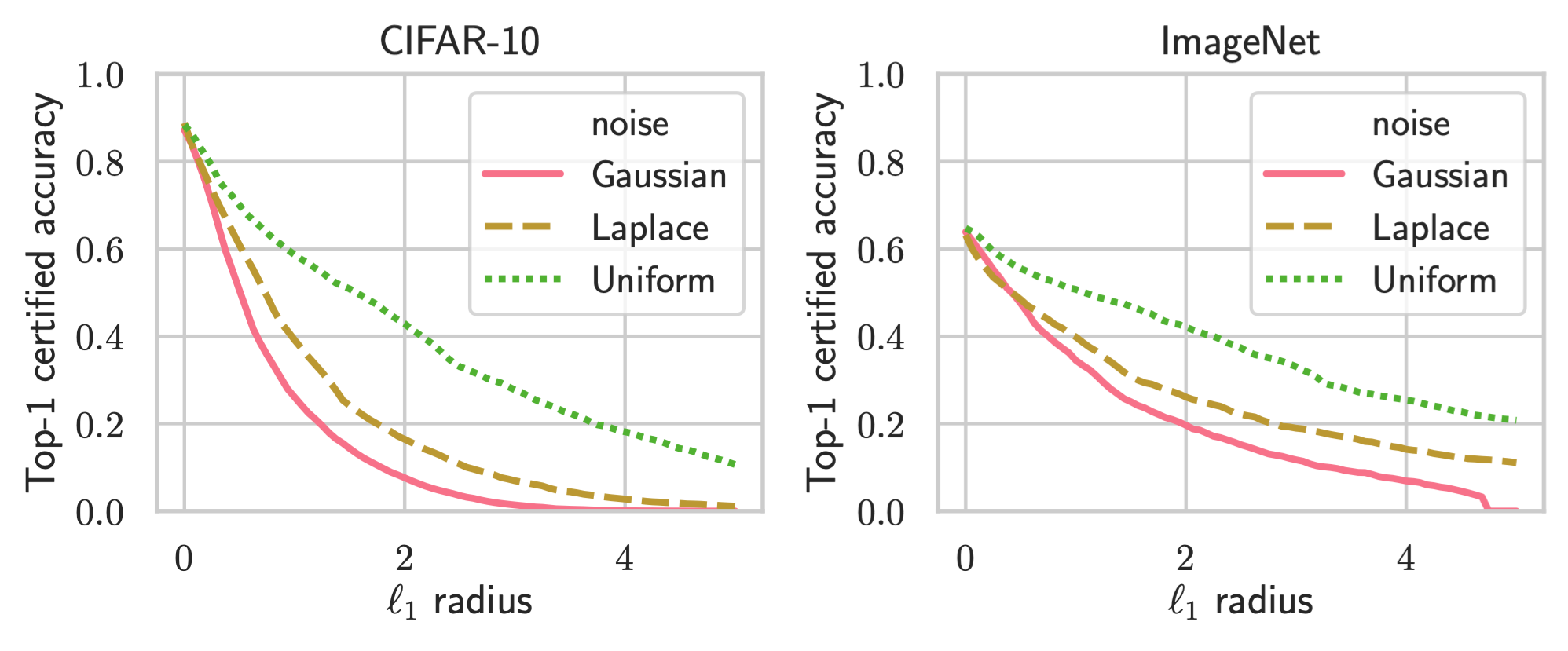
Conclusion
In this blog post, we reviewed randomized smoothing as a defense against adversarial examples. We answered the important question of how to choose an appropriate smoothing distribution for a given adversary. Empirically, our methods yield state-of-the-art performance for robustness. Our paper contains other results that we have not discussed here, like how to calculate robust radii for non-Gaussian distributions and a theorem on the limits of randomized smoothing. We shall cover these in other blog posts, but the reader is welcome to check out the paper in the mean time.
This blog post presented work done by Greg Yang, Tony Duan, J. Edward Hu, Hadi Salman, Ilya Razenshteyn, and Jerry Li. We would like to thank Huan Zhang, Aleksandar Nikolov, Sebastien Bubeck, Aleksander Madry, Jeremy Cohen, Zico Kolter, Nicholas Carlini, Judy Shen, Pengchuan Zhang, and Maksim Andriushchenko for discussions and feedback.